고정 헤더 영역
상세 컨텐츠
본문
🏡DATA: House Price
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
🟡 Description
- 주택 구매자에게 자신이 꿈꾸는 주택에 대해 설명하도록 요청하면 지하실 천장의 높이나 동서 철도와의 근접성으로 시작하지 않을 것입니다.
- 그러나 이 데이터 세트는 (그러한 특성이) 침실의 수나 흰색 울타리보다 가격 협상에 훨씬 더 많은 영향을 미친다는 것을 증명합니다.
- 아이오와주 에임스에 있는 주거용 주택의 (거의) 모든 측면을 설명하는 79개의 설명 변수가 있는 이 경쟁은 각 주택의 최종 가격을 예측하는 데 도전합니다.
- 평가는 RMSE로 평가하며, 비싼 집값과 싼 집값에 공평하게 영향을 미치고자 한다.
- 예를 들어 2억짜리 집을 4억으로 예측한 것이 100억짜리 집을 110으로 예측한 것보다 더 잘못예측함.
- 따라서 예측값의 로그 값으로 제출하라
✅ Case1. Train, Test set이 나눠져 있는 경우
1️⃣ 데이터로드
# 모든 컬럼(변수)가 다 보이게
pd.set_option('display.max_columns', None)
train = pd.read_csv(file_name[3], index_col="Id")
print(train.shape)
>>> (1460, 80)
test = pd.read_csv(file_name[2], index_col="Id")
print(test.shape)
>>> (1459, 79)
# 앞으로 봐야하는 정답값
set(train.columns) - set(test.columns)
>>> {'SalePrice'}
2️⃣ 데이터 탐색
1. 요약정보
trani.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1460 entries, 1 to 1460
Data columns (total 80 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MSSubClass 1460 non-null int64
1 MSZoning 1460 non-null object
2 LotFrontage 1201 non-null float64
3 LotArea 1460 non-null int64
.
.
.
76 YrSold 1460 non-null int64
77 SaleType 1460 non-null object
78 SaleCondition 1460 non-null object
79 SalePrice 1460 non-null int64
dtypes: float64(3), int64(34), object(43)
memory usage: 923.9+ KB
2. 기술통계값
- 수치형변수에 대한 기술통계값을 확인한다.
train.describe()
3. 히스토그램
- 수치형 변수의 분포를 확인
- 범주형 변수로 변환해줘야 할 피쳐가 있는지, 로그 변환이 필요한 피쳐가 있는지 확인함
train.hist(bins=50, figsize=(20, 15))

3️⃣ 데이터 전처리
1. 결측치 탐색
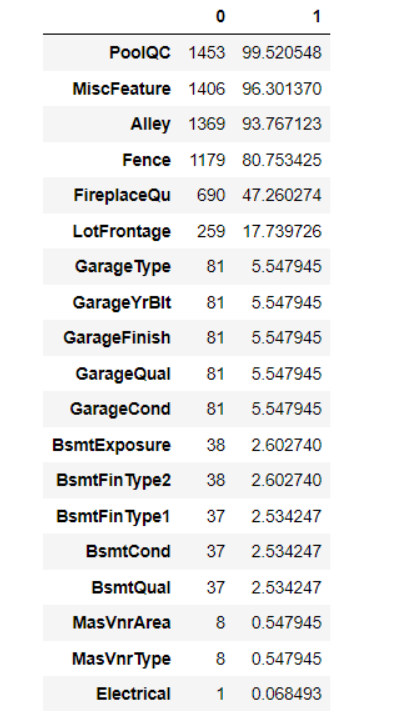
- 변수가 많을 때는 결측치가 있는 데이터만 가져온다
train_null = train.isnull().sum()
train_null_sum = train_summ[train_null != 0].sort_values(ascending=False)
train_null_sum
PoolQC 1453
MiscFeature 1406
Alley 1369
Fence 1179
FireplaceQu 690
LotFrontage 259
GarageType 81
GarageYrBlt 81
GarageFinish 81
GarageQual 81
GarageCond 81
BsmtExposure 38
BsmtFinType2 38
BsmtFinType1 37
BsmtCond 37
BsmtQual 37
MasVnrArea 8
MasVnrType 8
Electrical 1
dtype: int64
- 결측치 비율과 같이 보는 방법은 아래와 같다.
train_na_mean = train.isnull().mean() * 100
pd.concat([train_null, train_na_mean], axis=1).loc[train_null_sum.index]
2. 이상치 탐색
이상치로 추정되는 값의 범위를 정해 시각화를 통해 이상치를 탐색해보자
sns.scatterplot(data= train, x=train.index, y="SalePrice"
plt.axhline(40000, c="k", ls="-")
plt.axhline(50000, c="k", ls="-")

- train의 정답에 이상치가 있다면 어떻게 처리하는 것이 좋을까?
- train data의 경우 제거할 수 있다. 하지만 test는 제거할 수 없다.
- 변수 세분화하여 이상치 분리
- 너무 큰 값을 평균이나 중앙값으로 대체한다면 우리가 연예인이 사는 한남동 집을 평균 가격으로 조정하는 것과 같으며, 실제 값이 많이 왜곡될 수 있음에 주의해야 한다.
3. 희소값 탐색
# 전체 범주형변수에 대한 nunique()
train.select_dtypes(include="object").nunique().nlargest(10)
Neighborhood 25
Exterior2nd 16
Exterior1st 15
Condition1 9
SaleType 9
Condition2 8
HouseStyle 8
RoofMatl 8
Functional 7
RoofStyle 6
dtype: int64
# Neighborhood에 희소값이 있는지 살펴보자
trina["Neighborhood"].value_counts().sort_values(ascending=False)
NAmes 225
CollgCr 150
OldTown 113
Edwards 100
Somerst 86
Gilbert 79
NridgHt 77
Sawyer 74
NWAmes 73
SawyerW 59
BrkSide 58
Crawfor 51
Mitchel 49
NoRidge 41
Timber 38
IDOTRR 37
ClearCr 28
SWISU 25
StoneBr 25
MeadowV 17
Blmngtn 17
BrDale 16
Veenker 11
NPkVill 9
Blueste 2
sns.countplot(data = train, x="Neighborhood",
order = train["Neighborhood"].value_counts().index())

4️⃣ Feature Engineering
1. 스케일링
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustScaler
#StandardScaler
sc = StandardScaler()
train[["SalePrice_ss"]] = sc.fit(train["SalePrice"]).transform(train["SalePrice"])
#MinMaxScaler
mm = MinMaxScaler()
train[["SalePrice_ss"]] = mm.fit(train["SalePrice"]).transform(train["SalePrice"])
#RobustScaler
rb = RobustScaler()
train[["SalePrice_ss"]] = rb.fit(train["SalePrice"]).transform(train["SalePrice"])
print(train[["SalePrice", "SalePrice_ss", "SalePrice_mm", "SalePrice_rs"]].head())
print(train[["SalePrice", "SalePrice_ss", "SalePrice_mm", "SalePrice_rs"]].dsecribe())
print(train[["SalePrice", "SalePrice_ss", "SalePrice_mm", "SalePrice_rs"]].hist())

- 분포는 모두 동일하지만 x축의 값이 다른 것을 확인할 수 있다.
2. 로그 변환(log transform)
# 로그변환
train["SalePruce_log1p"] = np.log1p(train["SalePrice"]
# 로그변환 후 스케일링
train["SalePrice_lop1p_ss"] = ss.fit_transform(train[["SalePrice_log1p"]])
# 스케일링 후 로그변환
train["SalePrice_ss_log1p"] = np.log1p(train["SalePrice_ss"])
train[['SalePrice_ss',"SalePrice_ss_log1p", 'SalePrice_log1p','SalePrice_log1p_ss']].describe()

- 정규분포를 만들려면 스케일링 후 로그를 취하는 것이 아니라, 로그를 취한 후 스케일링을 해주는 것이 정규분포에 더 가까워진다.
- 로그변환만 해줘도 정규분포 형태가 되며, 여기서 표준화 스케일링을 해주면 표준정규분포 형태가 된다.
3. 이산화
# pd.cut(bins=, label)
train["SalePrice_cut"] = pd.cut(train["SalePrice"], bins=4, label=[1, 2, 3, 4])
# pd.qcut(q, label)
train["SalePrice_cut"] = pd.cut(train["SalePrice"], q=4, label=[1, 2, 3, 4])
display(train["SalePrice_cut"].value_counts())
display(train["SalePrice_cut"].value_counts(1))
display(train["SalePrice_qcut"].value_counts().sort_index())
display(train["SalePrice_qcut"].value_counts(1).sort_index())

fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12,3))
sns.countplot(data = train, x="SalePrice_cut", ax = axes[0])
sns.countplot(data = train, x="SalePrice_qcut", ax = axes[1])

SalePrice_cut 은 SalePrice를 히스토그램으로 그린것과 같다.
4. 인코딩
🟠 Pandas를 사용한 인코딩
Ordinal Encoding : .cat.codes
train["MSZoning"].astype("category").cat.codes
[ RL, RM, FV, RH, C(all)] ⇒ [3, 4, 1, 2, 0]으로 인코딩된다.
pd.get_dummies
pd.get_dummies(train["MSZoning"])
🟠 sklearn을 사용한 인코딩
# Label encoding
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(["paris", "paris", "tokyo", "amsterdam"])
print(list(le.classes_))
>>> ['amsterdam', 'paris', 'tokyo']
print(le.transform(["tokyo", "tokyo", "paris"]))
>>> [2 2 1]
# 인코딩값 다시 불러오기
list(le.inverse_transform([2, 2, 1])
>>> ['tokyo', 'tokyo', 'paris']
# Ordinal Encoding
from sklearn.preprocessing import OrdinalEncoder
enc = OrdinalEncoder()
X = [['male', 'from US', 'uses Safari'],
['female', 'from Europe', 'uses Firefox']]
enc.fit(X)
print(enc.transform([['female', 'from US', 'uses Safari']])
>>> [[0. 1. 1.]]
❓ Label Encoder와 Ordinal Encoder의 차이?
- ordinal encoder는 label encoder와 달리 변수의 순서를 고려한다. 즉 label 변수의 순서 정보를 사용자가 지정해서 다을 수 있다.
- LabelEncoder는 입력이 1차원 y값, OrdinalEncoder는 2차원 X값
# Onehot Encoding
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
X = [['male', 'from US', 'uses Safari'],
['female', 'from Europe', 'uses Firefox']]
enc.fit(X)
enc_out = enc.transform([['female', 'from US', 'uses Safari'],
['male', 'from Europe', 'uses Safari']]).toarray()
print(enc_out)
>>> [[1. 0. 0. 1. 0. 1.],[0. 1. 1. 0. 0. 1.]]
print(enc.get_feature_names_out())
>>> ['x0_female' 'x0_male' 'x1_from Europe' 'x1_from US' 'x2_uses Firefox'
'x2_uses Safari']
pd.DataFrame(enc_out, columns=enc.get_feature_names_out())

- 원핫 인코딩은 enc.get_feature_names_out()과 pd.DataFrame(enc_out, columns = enc.get_feature_names_out())으로 데이터프레임을 만들어줘야한다.
# train과 test에 있는 MSZoning 원핫인코딩해보기
# handle_unknown: 변환 중에 알 수 없는 범주 기능이 있는 경우 오류발생의 여부
# 역변환할 경우 알수없는 범주는 없음으로 표시된다.
ohe = OneHotEncoder(handle_unknown="ignore")
# train은 fit_transform()
train_ohe = ohe.fit_transform(train[["MSZoning", "Neighborhood"]]).toarray()
# test는 transform만!
test_ohe= ohe.transform(test[["MSZoning", "Neighborhood"]])
# 인코딩 후 train과 test의 피처수가 같은지 확인 필요
print(train_ohe.shape, test_ohe.shape)
>>> (1460, 30)
pd.DataFrame(train_ohe, columns = ohe.get_feature_names_out())
5. 파생변수: 다항식 전개(Polynomial Expansion)
- uniform한 데이터에 적용하는 것이 좋다
- uniform하다는 균등하다는 의미이다. 히스토그램을 그렸을 때 어딘가 많고, 어딘가 적은 데이터가 있다면 그것도 특징이 될 수 있기 때문이다.
from sklearn.preprocessing import PolynomialFeatures
house_poly = poly.fit_transform(train[["MSSubClass", "LotArea"]])
pd.DataFrame(house_poly, columns = poly.get_feature_names_cout())
6. 특성 선택: Feature Selection
🟡 분산 기반 필터링
- 범주형 변수 중에 어느 하나의 값에 치중되어 분포되어있지 않은지 확인하다.
for col in train.select_dtypes(include="object").columns:
print(train[col].value_counts(1)*100)
print('-'*30)
RL 78.835616
RM 14.931507
FV 4.452055
RH 1.095890
C (all) 0.684932
Name: MSZoning, dtype: float64
------------------------------
Pave 99.589041
Grvl 0.410959
Name: Street, dtype: float64
------------------------------
Grvl 54.945055
Pave 45.054945
Name: Alley, dtype: float64
----------------------------이런식으로 나오게 되는데, 컬럼의 개수가 많으면 출력값이 길어지므로, 변수의 한 값의 비율이 90%가 넘는 값만 출력되게하다
for col in train.select_dtypes(include="object").columns:
if train[col].value_counts(1)[0]*100 >= 90;
print(col)
Street
Utilities
LandSlope
Condition2
RoofMatl
BsmtCond
Heating
CentralAir
Electrical
Functional
GarageQual
GarageCond
PavedDrive
MiscFeature위의 결과값은 피쳐의 한 unique값이 전체의 90%이상을 차지하는 값을 갖고 있는 피처들이다. 한 피처를 골라 확인해보자
print(train["RoofMatl"].value_counts())
sns.countplot(data=train, x="RoofMatl")
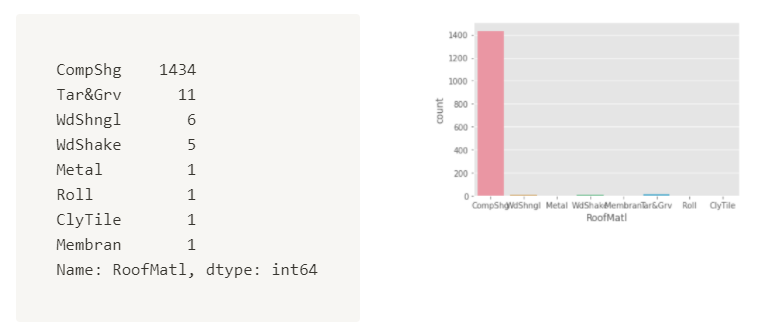
- 이러한 값들의 경우 분석에서 제외해주거나, 나머지 값들을 etc로 묶어서 분석하는 것도 한 방법이 될 수 있다.
🟡 상관관계 기반 필터링
corr = train.corr
mask = np.triu(np.ones_like(corr))
plt.figure(figsize=(25,25))
sns.heatmap(corr, cmap="coolwarm", annot=True, mask = mask,
vmin=-1, vmax=1, fmt = '.2f')





