멋사 AISCOOL 7기 Python/INPUT
[크롤링 & EDA] 메인 및 상세 페이지 수집 함수 만들기: 서울특별시 다산콜센터의 주요 민원
dundunee
2022. 10. 26. 22:43
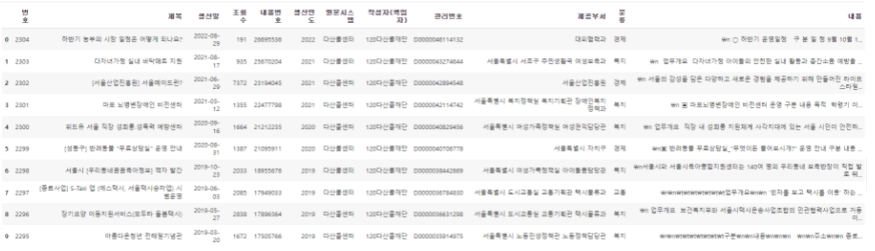
서울특별시 120 전체 페이지 목록에 포함된 번호, 제목, 생산일, 조회수와 더불어 상세페이지에서 알 수 있는 내용번호, 내용, 분류까지 불러오는 데이터프레임을 만드는 것이 목적이다.
step1. 라이브러리로드
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup as bs
import time
from pandas.io.pytables import TableIterator
from tqdm.notebook import tqdmstep2. 메인페이지(목록 + 상세페이지로 이동가능한 내용번호가 포함된)를 불러오는 함수
def get_one_page(page_no):
#1: page_no 마다 url이 변경되게 f-string을 사용해서 만든다.
base_url = f"https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page={page_no}"
#2: pd.read_html을 사용해서 테이블태그를 읽어온다.
#3: 3)별과에서 0번의 인덱스를 가져와 데이터프레임으로 목록의 내욜을 만든다.
table = pd.read_html(response.text, encoding = "utf-8")[0]
#페이지의 목록데이터프레임이 만들어질때만 함수를 진행해야함.
if table.shape[0] == 0:
return f"{page_no}페이지를 찾을 수 없습니다."
try:
#4: requests를 사용해서 요청을 보내고, 응답을 받는다.
response = requests.get(base_url)
#5: html tag를 parsing할 수 있게 bs형태로 만든다.
html = bs(response.text)
#6: 목록 안에 있는 a tag를 찾는다.
a_list = html.select('td.data-title.aLeft > a')
#7:a tag안에서 string을 분리해서 내용번호만 리스트 형태로 만든다.
a_link_no = []
for a_tag in a_list:
a_link_no.append(a_tag["href"].split("/")[-1])
# a_link_no = [a_tag["href"].split("/")[-1] for a_tag in a_list]
# df["내용번호"] = [a_tag["href"].split("/")[-1] for a_tag in a_list]
#8:4)의 결과에 "내용번호"라는 컬럼을 만들고 a tag의 리스트를 추가한다
table["내용번호"] = a_link_no
except:
# 중간에 오류가 발생해도 다음 코드를 실행해야 할 때는 예외메시지만 출력하도록 하는 방법도 있습니다.
return f"{page_no}페이지를 찾을 수 없습니다."
#raise Exception (f"{page_no}페이지를 찾을 수 없습니다.") #오류 + 메시지가 함께 출력
return tablestep3. 반복문을 사용해서 메인페이지 전체(=콜센터 페이지에 있는 모든 목록) 받아오기
page_no = 1
table_list = []
# 수집해야할 페이지가 최종적으로 몇페이진지 알아볼 수 있음
while True:
print(page_no, end=",")
df_temp = get_one_page(page_no)
if type(df_temp) == str :
print("수집이 완료되었습니다.")
break
table_list.append(df_temp)
page_no = page_no + 1
time.sleep(0.01)step4. 메인페이지 수집을 완료한 최종데이터프레임
df = pd.concat(table_list)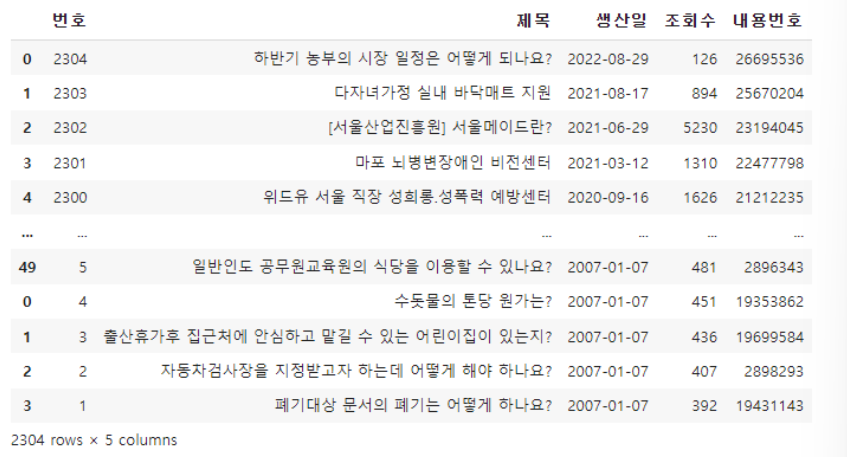
step5. 상세페이지의 테이블태그로 이뤄진 문서정보 부분 수집하는 함수
def get_desc(response):
""" 분류 수집하기 """
table = pd.read_html(response.text)[-1]
tb01 = table[[0, 1]].set_index(0).T
tb02 = table[[2, 3]].set_index(2).T
tb02.index = tb01.index
df_desc = pd.concat([tb01, tb02], axis=1)
return df_desc
get_desc(response)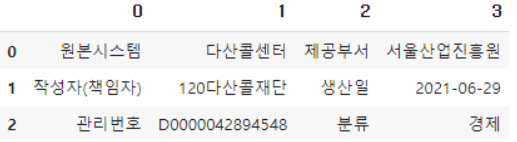

step6. 상세페이지의 문서정보와 문서내용을 수집하는 함수
def get_view_page(view_no):
"""
1) url만들어주기
2) requests로 요청보내기
3) 문서내용수집
4) 문서정보수집
5) time.sleep으로 쉬어가기
6) 반환
"""
url = f"https://opengov.seoul.go.kr/civilappeal/view/?nid={view_no}"
response = requests.get(url)
html = bs(response.text)
content = html.select('div.view-content.view-content-article > div > div.line-all')[0].get_text()
df_desc = get_desc(response)
df_desc["내용"] = content
df_decs["내용번호"] = view_no
time.sleep(0.01)
return df_descstep7. 상세페이지 전체를 받아오는 함수
tqdm.pandas()
view_detail = df["내용번호"].progress_map(get_view_page)step8. 상세페이지에 대한 최종 데이터프레임
df_view = pd.concat(view_detail.tolist())
step9. 메인페이지와 상세페이지 결합 및 파일에 저장하고 불러오기
df_detail = df.merge(df_view, on=["내용번호","생산일"])
#원하는 정보만 가져오가
df = df_detail[['번호', '분류', '제목', '내용', '내용번호']]
#저장하고 불러오기
file_name = "seoul-120-sample.csv"
df.to_csv(file_name, index = False)
pd.read_csv(file_name)