멋사 AISCOOL 7기 Python/INPUT
앤스컴 콰르텟
dundunee
2022. 9. 22. 22:31
앤스컴 콰르텟(Anscombe's quartet)는 기술통계량은 유사하지만 분포나 그래프는 매우 다른 4개의 데이터셋이다. 각 데이터셋은 11개의 (x, y) 좌표로 이루어진다. 1973년, 통계학자인 프란시스 앤스컴(Francis Anscombe)이 데이터 분석 전 1) 시각화의 중요성과 2) 특이치 및 주영향관측값(influential observation)의 영향을 보여주기 위해 만들었다. 그는 "숫자 계산은 정확하지만, 그래프는 거칠다"는 통계학자들의 통념을 상쇄하기 위한 목적이었다고 설명했다.
라이브러리 로드
import pandas as pd
import seaborn as sns
import numpy as np데이터 로드
github에서 제공하는 anscombe.csv 데이터를 이용하고자 한다.
sns.load_dataset("anscombe")
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/anscombe.csv")데이터 셋 나누기 및 기술통계량 추출: df.groupby("dataset")[["x", "y"]].describe()

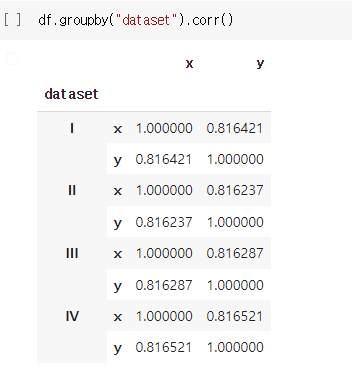
기술통계량과 상관계수가 4개의 데이터셋에서 거의 동일하게 나타남. 따라서 자료의 구성과 분석 결과 혹은 데이터의 패턴이 모두 동일할 것이라 추측할 수 있다.
seaborn 라이브러리의를 사용한 시각화: lmplot

시각화 결과 데이터 셋이 데이터분포는 모두 다름을 확인할 수 있으며, 따라서 이를 통해 데이터시각화의 중요성을 알 수 있다.