고정 헤더 영역
상세 컨텐츠
본문 제목
[머신러닝] Titanic 데이터를 사용한 분류: Feature Engineering(결측치 보간법) + 하이퍼파리미터튜닝(RandomizedSearchCV)
본문
✅ Feature Engineering(결측치 보간법) + Random Forest + 하이퍼파리미터튜닝(RandomizedSearchCV)
1️⃣ 결측치 보간법
- 이전 값이나 다른 값으로 채울 수 있음
- 이런 방법은 대부분 시계열 데이터에서 데이터가 순서대로 있을 떄 사용함
- 예를 들어 일자별 주가 데이터가 있다고 가정할 때 중간에 빠진 날짜에 대한 데이터를 채울때 사용하거나, 순서가 있는 센서 데이터에서 수집이 누락되어 앞 뒤값에 영향을 받는 데이터를 채울 때 사용한다.

train["Age_fill"] = train["Age"]
train["Age_fill"] = train["Age"].fillna(method="ffill")
train["Age_fill"] = train["Age"].fillna(method="bfill")
# 보간법
train["Age_interpol"] = train["Age"].interpolate(method="linear", limit_direction="both")
train[["Age", "Age_ffill", "Age_bfill", "Age_interpol"]].head()
# test도 마찬가지로 채워준다
# ESC + F
test["Age_ffill"] = test["Age"].fillna(method="ffill")
test["Age_bfill"] = test["Age"].fillna(method="bfill")
test["Age_interpol"] = test["Age"].interpolate(method="linear", limit_direction="both")
test[["Age", "Age_ffill", "Age_bfill", "Age_interpol"]]ㅠ.
2️⃣모델링
label_name = "Survived"
feature_names = ["Pclass", "Sex", "Age_interpol", "Fare_fill", "Embarked"]
X_train = pd.get_dummies(train[feature_names])
X_test = pd.get_dummies(test[feature_names])
y_train = train[label_name]
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
3️⃣하이퍼파라미터 튜닝
- GridSearch의 단점은 지정된 조합만 보기 때문에 해당 그리드를 벗어나는 곳에 좋은 성능을 내는 하이퍼파라미터가 있다면 찾지 못하는 단점이 있다.
- RandomizedSearchCV는 랜덤한 값을 넣고 하이퍼파라미터를 찾는다. 처음에는 범위를 넓게 지정하고, 그 중에 좋은 성능을 내는 범위를 점점 좁혀가며 찾아야한다.
from sklearn.model_selection import RandomizedSearchCV
param_distribution = {"max_depth": np.random.randint(3, 100, 10),
"max_features": np.random.uniform(0, 1, 100)}
✅ Python의 Numpy는 효율적으로 무작위 샘플을 만들 수 있는 numpy.random 모듈을 제공하고 있다.
np.random.uniform(low, high, size) 균등분포로부터 무작위 표본 추출
np.random.randint(low, high, size) 이산형 균등분포에서 정수형 무작위 표본 추출
clf = RandomizedSearchCG(estimator=model,
param_distributions = param_distributions,
n_iter = 5,
n_jobs = -1,
random_state=42)
clf.fit(X_train, y_train)
clf.best_estimator_
>>> RandomForestClassifier(max_depth=58, max_features=0.7754808538715331, n_jobs=-1,
random_state=42)
clf.best_score_
>>> 0.8081413596133326
pd.DataFrame(clf_cv.result_).sort_values("rank_test_score").head()
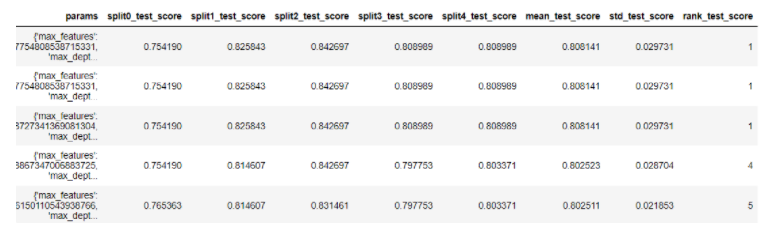
• Fitting 5 folds for each of 5 candidates, totalling 25 fits
- 5 fold 는 cv 조각 5개를 의미하며 5 candidates 는 n_iter를 의미합니다.
❓질문❓
- cross validation은 반드시 해야 하나요?애당초 모델을 만들 때 트레이닝셋이랑 테스트셋을 7:3 정도로 나누는데 이 자체가 cross validation을 하는 거 아닌가요?
- cv는 교차 검증의 과정이다. 위에서 말한 것은 holdout validation!
- 7:3이나 8:2로 나누는 과정은 hold-out-validation이다. 이것의 단점은 train:valid가 7:3이라면 중요한 데이터가 3에만 있어서 제대로 학습되지 못하거나 모든 데이터가 학습에 사용되지 않는다. 그래서 모든 데이터가 학습과 검증에 사용하기 위해서 cross validation을 한다.
- 또한 cross validation은 속도가 오래걸린다는 단점이 있기도 하지만 validation의 결과에 대한 신뢰가 중요할 때 사용한다. 예를 들어 사람의 생명을 다루는 암 여부를 예측하는 모델을 만든다거나 한다면 좀 더 신뢰가 있게 검증할 필요가 있다.
- 대신 hold-out-validation은 한번만 나눠서 학습하고 검증하기 때문에 빠르다는 장점이 있으나, 신뢰가 떨어지는 단점이 있다. 하지만 당장 비즈니스에 적용해야하는 문제에 빠르게 검증해보고 적용해보기에 좋다.
- cross validation이 너무 오래 걸린다면 조각의 수를 줄이면 좀 더 빠르게 결과를 볼 수 있고, 신뢰가 중요하다면 조각의 수를 좀 더 여러개 만들어 보면 된다.
4️⃣정확도
best_model = clf.best_estimator_
y_predict = best_model.fit(X_train, y_train).predict(X_test)
sns.barplot(x=best_model.feature_importances_, y=best_model.feature_names_in_)

'멋사 AISCOOL 7기 Python > INPUT' 카테고리의 다른 글
| [KMOOC-실습으로배우는머신러닝]2. Machine Learning Pipeline (0) | 2022.11.21 |
|---|---|
| [KMOOC-실습으로배우는머신러닝] 1. Introduction to Machine Learning (0) | 2022.11.21 |
| [머신러닝] Titanic 데이터를 사용한 분류: Feature Engineering(파생변수 생성, 원핫인코딩,결측치 대체), Cross Validation (1) | 2022.11.17 |
| [머신러닝] Titanic 데이터를 사용한 분류: Decision Tree, Binary Encoding, Entropy (0) | 2022.11.17 |
| [머신러닝] pima 데이터를 사용한 분류: Random Forest (0) | 2022.11.17 |




