고정 헤더 영역
상세 컨텐츠
본문 제목
[머신러닝] INTRO. 머신러닝프로젝트 주요단계(전처리, EDA, Feature Engineering, 교차검증, 하이퍼파라미터튜닝)
본문
1️⃣ step1. 데이터 수집 → 전처리 → EDA
- Feature engineering을 위한 단계로 볼 수 있다.
1) 데이터 탐색
- .info(), .select_dtypes()매서드를 이용해서 데이터프레임에 대한 요약정보 확인
- 이를 통해 범주형(Categorical) 및 수치형(Numeric) 변수(Features)가 얼마나 있는지 확인할 수 있음
2) 결측치(Missing Value) 탐색
- 결측치란, Feature가 적절한 값을 갖지 못하고 무의미한 값을 갖는 경우를 의미한다.
- None, Null, Nan, 공백 등 다양한 값으로 존재하며 잘 처리해줘야한다.
- .isnull().sum(), .isnul().sum().mean()
3) 이상치(Outlier)
- 이상치란 Feature에서 일반적인 값 분포에서 벗어나는 경우를 의미한다.
- 이상치를 찾는 방법에는 (1) 값의 범위를 지정하여 범위에서 벗어나는 값을 찾거나 (2) 데이터를 시각화하여 그래프에서 눈에 띄는 값을 찾는다.
- 이상치는 데이터 해석이나 머신러닝 모델의 학습을 방해하기 때문에 이상치를 제거하거나, 적절한 값으로 변환해주는 것이 필요하다.
- 평균값, 중앙값, 머신러닝 예측모델 사용, 시계열 데이터의 경우 직전 혹은 직후 값을 사용
4) 희소값(Rare Values)
- 범주형 데이터에서 빈도(Frequency)가 낮은 값을 희소값이라고 한다.
- 희소값은 데이터 해석을 어렵게 하고 머신러닝 성능을 낮출 수 있기 때문에 적절히 처리해줘서 전체 경향이 뚜렷하게 드러나게 만들어야 한다
- 희소값들을 병합함으로써 원핫인코딩에서 피쳐의 수를 줄여주기도 한다.
- 다만 희소값들이 중요한 경우가 있으니 이는 주의해야한다.
- 따라서 희소한 값을 사용하고자 한다면 의사결정이 필요하다
-
- 아예 희소값을 결측치 처리하면 ond-hot-encoding하지 않는다.
- 희소값을 기타로 묶어줄 수 있다
-
2️⃣ step2. Feature Engineering
💡 Feature의 종류
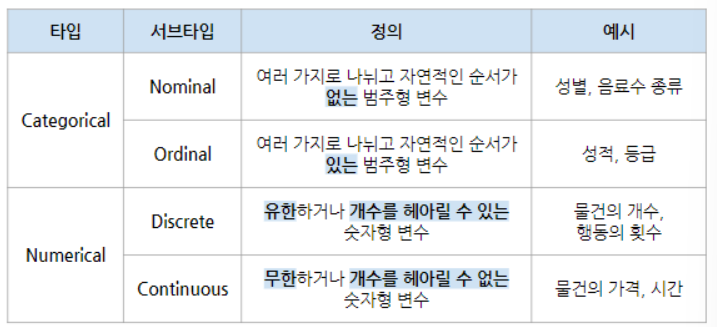
1) Feature Selection
- 전문적 지식 및 특성의 중요도(feature importance)에 따라 일부 특성을 버리거나 선택한다
- 비교적 중요하지 않은 Feature를 제거하며 과대적합을 방어한다.
분산 기반(Variance Based) Feature Selection
- 어떤 feature들은 대부분 값이 때때로 전부가 가은 값을 갖거나 다른 값을 가지면 그 feature는 무언가를 예측하는데 도움이 되지 않을 수 있다.
- 단 이는 머신러닝 모델을 위한 Feature selection을 말하는 것이며, 상황에 따라 특정 feature가 변동성이 낮다는 것도 중요한 정보가 될 수 있다.
상관관계 기반(Correlation Based) Feature Selection
- 어떤 feature들의 상관관계가 높다면 하나만 채택해도 된다 → 다중공선성의 이유
트리 기반 머신러닝 모델을 이용한 Feature Importance
- sklearn의 지니 중요도를 이용해서 트리기반 모델의 feature importance를 계산한다.
- 이것은 참고가능한 지표이지 절대적인 지표는 아니다.
- 엄밀히 말하면 feature engineering에서 벗어난다고 볼 수 있다.
2) Feature Extraction
- PCA를 사용하여 Feature에서 새로운 특성을 추출한다.
3) Scaling
- 변수의 분포가 편향되어 있는 경우 범위를 조정하여 정규화하는 것
- 일반적으로 피처의 분산과 표준편차를 조정하여 정규분포 형태를 띄게하는 것이 목표이다.
- 변수의 분산과 편차를 바꾸고 싶거나, 변수간 규모 차이가 너무 나서 모델에 큰 영향을 미친다면 스케일링을 해주어야 한다.
- Feature Scaling이 잘 되어있다면 서로 다른 변수끼리 비교하는 것이 편리하며, Feature Scaling 없이 작동하는 알고리즘에서 더 빨리 작동한다.
- 경사하강법뿐만 아니라 KNN, Clustering과 같은 거리 기반 알고리즘에서 더 빨리 작동한다.
- Feature Scaling이 잘 되어있으면 머신러닝 성능이 상승하며, 일부는 이상치에 대한 강점이 있다.
- 트리기반 모델은 정보 균일도를 기반으로 되어있기때문에 피처 스케일링이 필요하지않다.
- 데이터의 절대적인 크기보다 상대적인 크기에 영향을 받기 때문이다. 스케일링을 해도 상대적 크기 관계는 같게 된다.
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustdScaler
- StandardScaler는 평균이 0, 표준편차가 1이다.
- MinMaxScaler는 최소값이 0, 최대값이 1이다.
- RobustScaler는 중앙값을 0으로 만든다.
❓ 표준정규분표와 그냥 정규분포 두 개 중에는 모델에서 사용할 때 성능차이가 많이 나나요?
- 트리계열 모델을 사용한다면 일반 정규분포를 사용해도 무관하나 스케일링값이 영향을 미치는 모델에서는 표준 정규분포를 만들어 주면 더 나은 성능을 낼 수 있다.
- 단 표준정규분포를 만들어갈 때 왜곡될 수 있기 때문에 주의가 필요하며, 꼭 이런 변환 작업을 많이해준다고 해서 모델의 성능이 좋아진다고 보장할 수 없다. 상황에 맞는 변환방법을 사용하는 것이 더 좋다.
- 그래서 스케일링을 먼저 하는 것 보다 로그를 적용한 후 스케일링으로 바꿔주는 것이 순서에 맞다
❓ 왜 데이터를 정규분포 형태로 만들어주면 머신러닝이나 딥러니에서 더 나은 성능을 낼까?
- 피처의 범위가 다르면 피처간 비교가 어려우며 거리기반 알고리즘에서는 머신러닝이 제대로 작동하지 않을 수 있다.
- 너무 한쪽에 몰려 있거나 치우쳐져 있을 때 보다 고르게 분포되어 있다면 데이터의 측성을 더 고르게 학습할 수 있다.
4) Transform: Log Transformation
- Feature들이 충분한 정보를 갖고 있더라도 새로운 Feature를 생성하는 것이 더 특징을 잘 보여줄 수 있다.
- 표준정규분포 형태로 만들기 위해서 Log Transformation이 필요하다.
- 스케일링이 잘 되었어도 아직 표준정규분포형태가 아니기 때문이다.
- Log Transformation은 log함수가 x값에 대해 상대적으로 작은 스케일에서는 키우고, 큰 스케일에서는 줄여주는 효과가 있기 때문이다.
- 정규분포가 중요한 이유!
- 값이 고르게 분포되었다는 것은 y값을 예측하는데 더 유리하다.
- 로그함수는 x값이 커질수록 기울기가 완만해지고 y값의 변화량이 작아지며, x값이 작을수록 y변화량이 크다. 이는 작은 숫자들 사이의 차이는 벌어지고, 큰 숫자들 사이의 차이는 줄어들 것이다.
- 그래서 편향된 피쳐의 경우 log가 적용된 값은 원래 값에 비해 더 고르게 분포하게 된다.
- 정규분포가 중요한 이유!
- 단 log transformation을 적용할 때 주어진 값에 1을 더해서 log transform을 해주는 것이 안전하다. ⇒ np.log1p()
- 다시 원래값으로 돌리려면 지수를 씌워준다. ⇒ np.expm1
❓ 음수인 값이 너무 뾰족하거나 치우쳐져 있어서 로그를 취하기 위해서는 어떻게 전처리해야 할까?
- 모든 값이 양수이거나 1보다 작은 값이 있을 떄는 1을 더해주면 된다.
- 너무 큰 음수 값이 있을 때는 최솟값 + 1을 더해준다. 예를 들어 -1000이 가장 작은 값이라면 1001을 모든 값에 더하고 로그 변환을 해준다. 이를 다시원래 값으로 복원하려면 지수함수로 변환후 -1001(np.exp(x)-1001)을 해준다.
5) Binning: 이산화
- 수치형 변수만으로 경향을 보기 어려울 때 수치형 변수를 묶어서 범주형 변수로 만들어준다.
- 이산화와 같은 과정이 우리의 사고방식과 부합하는 측면이 있어 직관적이며, 데이터 분석과 머신러닝에 유리하다.
- 유사한 예측 장도를 가진 유사한 속성을 그룹화하여 모델 성능을 개선하는데 도움이 될 수 있으며, 수치형 변수로 인한 과대적합을 방지할 수 있다.
- 범위를 기준으로 나누는 이산화(Equal width binning)과 빈도를 기준으로 나누는 이산화(Equal frequency binning)이 있다.
- Equal width binning : pd.cut()
- 전체 수치 범위에 대해 n분할 하는 것
- 가능한 값의 범위를 동일한 너비의 n개의 bins로 나눈다.
- 절대평가, 히스토그램, 고객을 구매 금액 구간에 따라 나눌 때
- Equal frequency binning : pd.qcut()
- 변수의 가능한 값 범위를 n개의 bins로 나누는 것
- Equal width binning에 비해 알고리즘 성능을 높이는데 도움이 될 수 있다.
- 상대평가, 고객을 나눌 때 고객의 수를 기준으로 등급을 나눌 때
6) Dummy: Encoding
- 범주형 변수를 수치형 변수로 바꾸는 방법이다.
- 데이터 시각화와 머신러닝 모델이 유리하다.
- 선형회귀모델, 딥러닝모델등은 범주형변수를 이용할 수 없다.
Ordinal-Encoding
- 범주형 변수를 수치형 변수 중 ordinal feature로 변환시켜 준다. 즉 값이 유한하여 정수형태이다.
- 직관적이고 복잡하지 않으며 간단하다. 하지만 데이터에 추가적인 가치를 더해주지 않는다는 단점이 있다.
- 특히 값의 크고 작음 혹은 순서에 의미가 있을 떄는 잘못된 해석이 될 수 있다. → Label encoding
- pandas에서 cat 속성의 codes 속성으로 지원한다: .cat.codes
- sklearn에서 OrdinalEncoder 객체로 지원하고 있다: **OrdinalEncoder()**
One-Hot-Encoding
- 범주형 변수를 다른 boo변수(0 또는 1)로 대체하여 해당 관찰에 대해 특정레이블이 참인지 여부를 나타낸다.
- 해당 feature의 모든 정보를 유지한다는 장점이 있으나, 해당 feature의 고유값이 지나치게 많은 경우 계산에 오래 걸리는 단점이 있다.
- pandas에서 get_dummies 메서드를 지원한다: pd.get_dummies
- sklearn에서 OneHotEncoder 객체로 지원한다: OneHotEncoder
7) Feature Generation: 파생변수
- 변수생성은 이미 존재하는 변수로부터 여러가지 방법을 이용해 새로운 변수를 만들어내는 것이다.
- 사칙연산, 최대값, 최소값, 산술평균 등 산술적인 방법으로 변수를 만들어낼 수 있다.
- 적절히 생성된 파생변수는 데이터의 특성을 더 잘 설명한다.
- 파생변수 생성으로 인해 성능이 올라갈 수도 있으나 역효과가 날수도 있다.
Polynomial Expansion
- 다항식 전개에 기반한 파생변수 생성법
- 주어진 다항식 차수 값에 기반하여 파생변수를 생성할 수 있다.
- 다항식 전개에 기반하여 파생변수를 만들게 되면 머신러닝 모델이 여러 feature에 기반하게 되어 안정성이 높아진다.
- 소수의 feature에 기반하게 되면 과대적합이 일어날 수 있다.
- sklearn에서 PolynomialFeatures 객체를 지원한다.
- degree 파라미처는 다항식의 최대차수를 지정한다.
3️⃣step3. 모델 학습 및 평가 ⭐
1) 전체 과정

2) 모델 평가: 교차검증
- Holdout validation
- training 데이터를 training validation으로 나눠서 검증함

- K-folds cross validation
- training 데이터를 k개 만큼 쪼갠 후 그중 k-1을 이용해 학습하고, 1개를 이용해 validation 하는 과정을 반복함.

3) 하이퍼파라미터 튜닝: perparameter search
💡 parameter(학습되는 값) vs hyperparameter(미리 설정해줘야 하는 값)
Grid search
- 모델의 하이퍼파라미터 후보군들을 완전 탐색하여 하이퍼 파라미터들를 검색
- 검증하고 싶은 하이퍼 파라미터 수치를 지정하면 수치별 조합을 모두 검증하여 최적의 파라미터 검색의 정확도 향상
- 후보군 개수가 많으면 많을수록 기하급수적으로 찾는 시간이 오래 걸리며 후보군들을 정확히 설정 필요
💡그리드 서치는 지정된 구간에 대한 값에 대해서 탐색한다. 반면 랜덤 서치는 지정된 구간 외에 최적값이 있을 때 그리드 서치로 찾지 못하는 단점을 보완하여 랜덤으로 값들을 지정하여 성능을 평가하고 그 중 가장 좋은 성능을 내는 파라미터를 찾음, 좋은 성능을 내는 구간으로 점점 좁혀가며 파라미처를 찾음.

💡굳이 validation을 해주지 않고 하이퍼파라미터튜닝만해줘도 됨! 그 안에 다 포함되어 있음
4) 성능 평가 지표
회귀 모델 평가지표

- RMSE: 오차가 클수록 가중치를 주게 됨(오차 제곱의 효과)
- RMSLE: 오차가 작을수록 가중치를 주게 됨(로그의 효과)
- 부동산 가격 같이 최솟값과 최댓값의 차이가 큰 값에 주로 사용된다
'멋사 AISCOOL 7기 Python > INPUT' 카테고리의 다른 글
| [머신러닝] pima 데이터를 사용한 분류: Random Forest (0) | 2022.11.17 |
|---|---|
| [머신러닝] pima 데이터를 사용한 분류: Decision Tree (0) | 2022.11.17 |
| [머신러닝] INTRO. Definition, Tool, 알고리즘 유형 (0) | 2022.11.17 |
| 시각화 총정리: plotly (1) | 2022.10.28 |
| 시각화 총정리: seaborn (0) | 2022.10.28 |




