고정 헤더 영역
상세 컨텐츠
본문
🚫Data: pima
• Pima Indians Diabetes Database | Kaggle
Pima Indians Diabetes Database
Predict the onset of diabetes based on diagnostic measures
www.kaggle.com
✅ 데이터 구성
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
1️⃣ 결정트리 학습법(Decision Tree learning)
- 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측모델로서 결정트리를 사용한다.
- 즉 예측 모델링 방법 중 하나이다.
- 분류트리: 트레 모델 중 목표 변수가 유한한 수의 값을 가짐
- 회귀 트리: 결정 트리 중 목표 변수가 연속하는 값, 일반적인 실수를 가짐
1.1.1 장점
- 결과를 해석하고 이해하기 쉽다.
- 자료를 가공할 필요가 거의 없다
- 수치 자료와 범주 자료 모두 적용할 수 있다.
- 화이트 박스 모델을 사용한다.
- 모델에서 주어진 상황이 관측가능하다면 boolean logic을 이용하여 조건에 대해 쉽게 설명할 수 있다.
- 반면 인공신경망은 대표적인 블랙박스모델로, 결과에 대한 설명을 이해하기 어렵다.
- 안정적이다.
- 대규모 데이터셋에도 잘 작동한다.
1.1.2 Decision Tree의 overfitting
- Decision Tree가 크고 복잡해질수록 과적합 발생 경향이 증가하며 이는 decision tree의 가장 고질적인 문제이다.
- 해결방법1. Pre-Pruning: 트리가 다 구성되기 전에 알고리즘을 중단한다.
- 해결방법2. Post-Pruning: 의사결정 나무를 최대수치까지 온전히 학습하고, 완성된 의사결정나무의 노드를 제거한다.
2️⃣ DecisionTreeClassifier: 분류트리
: 의사결정나무 분류
- 널리 사용되는 분류기 중 하나로, 복잡한 데이터에 대하여 좋은 성능을 보인다.
- 학습 데이터로부터 “설명가능”한 분류 기준을 결정한다.
- 데이터를 “뿌리”로 부터 말단의 “잎”까지 순차적으로 분류한다.
DecisionTreeClassifier(
*,
criterion='gini', # 분할방법 {"gini", "entropy"}, default="gini"
splitter='best',
max_depth=None, # The maximum depth of the tree
min_samples_split=2, # The minimum number of samples required to split an internal node
min_samples_leaf=1, # The minimum number of samples required to be at a leaf node.
min_weight_fraction_leaf=0.0, # The minimum weighted fraction of the sum total of weights
max_features=None, # The number of features to consider when looking for the best split
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
class_weight=None,
ccp_alpha=0.0,
)
- 주요 파라미터

2.1 불순도(Impurity)[1] - 지니 계수(Gini Index)

- 어떤 집합에서 한 항목을 뽑아 무작위로 라벨을 추정할 때 틀릴 확률을 말한다
- 집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표이며, 의사결정 나무의 분리가 잘 된것을 평가하기 위한 지표로 사용된다.
- How to Determine the Best Split

- Gini Index
- Entropy
- Misclassificaion error
- CART 알고리즘에서 사용한다.
- 0 ~1 사이의 값을 가지며, 0 은 최솟값이고 모든 데이터가 하나의 클래스에 속해있을 때를 의미힌다. 즉 지니계수가 0에 가까울 수록 그 클래스에 속한 불순도가 낮으므로 좋다.
- 반면 지니계수가 1에 가까울 경우 데이터들이 모든 클래스에 균일하게 분포할 때를 의미한다.
2.2 baseline
- step1-1. 학습, 예측 데이터 셋 및 컬럼 설정(1)
# train: test = 8:2로 나누기
split_count = int(df.shape[0] * 0.8)
train = df[:split_count] #(614, 9)
test = df[split_count:] #(154, 9)
# 학습, 예측에 사용할 컬럼
feature_names = df.columns.tolist()
# 정답컬럼제거
feature_names.remove("Outcome")
#정답값이자 예측할 값
label_name = "Outcome"
- 데이터 셋 만들기
X_train = train[feature_names]
y_train = train[label_name]
X_test = test[feature_names]
y_test = test[label_name]
- step1-2. 학습, 예측 데이터 셋 및 컬럼 설정(2)
# X, y를 만들어 줍니다.
X = df[feature_names]
y = df[label_name]
# train_test_split 으로 무작위로 데이터셋을 train 과 test 로 나눕니다.
# 분류문제에서는 stratify를 기본값으로 사용하는 것을 추천
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42)
- train_test_split
- stratify는 label의 클래스 분포를 균등하게 해준다. 즉 label 값을 같은 비율로 나눠준다.
- 머신러닝 알고리즘 가져오기 및 학습, 예측
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=3, max_features=0.98, random_state=42)
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
- 정확도 예측하기
# 방법1.
(y_test == y_predict).mean()
#방법2.
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
#방법3.
model.score(X_test, y_test)
>>> #0.7532467532467533
2.2.1 Decision Tree 시각화 및 지니계수 구하기
from sklearn.tree import plot_tree
plt.figure(figsize=(20,20))
plot_tree(model,
feature_names=feature_names,
filled=True,
fontsize=14)
plt.show()
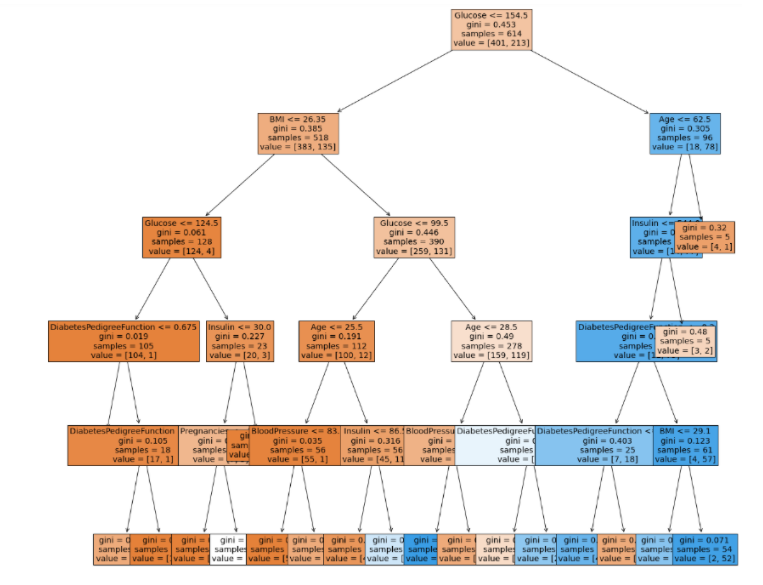
- gini = 0.453
- 1 - (401/614) ** 2 - (213/614) ** 2
- 1 - true값의 비율 제곱 - false값의 비율 제곱
- gini = 0
- 1 - (1/1) ** 2
- 가장 좋은 값, 아무것도 섞여있지않음
- gini = 1
- 1-(1/2) ** 2 - (1/2) ** 2
- 최악의 지니값
- sample은 샘플 수
- value=[T / F]: 발병확률에 대한
- value기준으로 샘플수가 또 나눠지는 건 아님
2.2.2 피쳐 중요도 추출
Decision Tree의 장점 중 하나는 피처 중요도를 추출할 수 있다는 점이다.
sns.barplot(x=model.feature_imporances_, y=model.feature_names_in_)

2.3 Feature Engineering
- 데이터의 성능을 높이는 방법 중 하나다.
2.3.1 수치형 변수 범주화
- 왜 범주형 변수로 만들까?
- 머신러닝 알고리즘에 힌트를 줄 수 있음
- 조건이 좀 덜 잘게 나눠져 과적합(overfitting)을 방지할 수 있음
- Pregnancies(임신횟수)가 6보다 큰 값을 True/False로 만들기
- df["Pregnancies_high"] = df["Pregnancies"] > 6
2.3.2 결측치 채우기
- 인슐린이 중요한 역할을 하는 것으로 보여지지만 결측치 비율이 상당히 높다. 따라서 인슐린 컬럼의 결측치를 채워준다.
# 새 컬럼 만들기
df["Insulin_nan"] = df["Insulin"].replace(0, np.nan)
# 발병여부에 따른 평균, 중앙값 구하기
# 0 값을 결측치로 만들지 않고 구할 때와 결측치로 만들고 구할때가 차이가 남
# 반드시 결측치형태로 만들고 구해줄 것
Insulin_mean = df.groupby("Outcome")["Insulin_nan"].mean()
>>>Outcome
0 130.287879
1 206.846154
# 결측치 채우기
df["Insulin_fill"] = df["Insulin_nan"]
df.loc[(df["Insulin_nan"].isnull())&(df["Outcome"]==0), "Insulin_fill"] = Insulin_mean[0]
df.loc[(df["Insulin_nan"].isnull())&(df["Outcome"]==1), "Insulin_fill"] = Insulin_mean[1]
2.3.3 이상치 다루기
- 이상치로 여겨지는 값들을 제외한다.
desc = df["Insulin_nan"].describe()
desc
>>>
#count 394.000000
#mean 155.548223
#std 118.775855
#min 14.000000
#25% 76.250000
#50% 125.000000
#75% 190.000000
#max 846.000000
IQR = desc['75%'] - desc['25%']
max_out = desc['75%'] + (1.5*IQR)
max_out
>>> #360.625
df = df[df["Insulin_fill"] < max_out]
df.shape
>>> #(744, 12)
2.3.4 모델링 및 정확도 평가
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=6, min_samples_leaf=6, random_state=42)
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
(y_test == y_predict).mean()
>>> #0.9261744966442953
sns.barplot(x = model.feature_importances_, y = model.feature_names_in_)

결론
- 피쳐 엔지니어링으로 모델의 정확도가 높아졌으며, 발병에 가장 많은 영향을 미칠것이라 예상했던 인슐린이 가장 중요한 피쳐로 추출됨
2.4 하이퍼파라미터 튜닝
하이퍼파라미터 : 머신러닝 모델을 생성할 때 사용자가 직접 설정하는 값으로, 이를 어떻게 설정하느냐에 따라 모델의 성능이 달라진다.
수동튜닝 : 만족할 만한 하이퍼파라미터들의 조합을 찾을 때 까지 수동으로 조절
GridSearhCV() : 시도할 하이퍼파라미터들을 지정하면 모든 조합에 대해 교차검증 후 가장 좋은 성능을 내는 하이퍼파라미터 조합을 찾음
RandomizedSearchCV() : GridSearch와 동일한 방식으로 사용하지만 모든 조합을 다 시도하지 않고, 각 반복마다 임의의 값만 대입해 지정한 횟수만큼 평가
🛠️ GridSearchCV
# 파라미터 후보 설정
parameters = {"max_depth":list(range(3, 18, 2)),
"max_features":[0.3, 0.5, 0.7, 0.8, 0.9]}
from sklearn.model_selection import GridSearchCV
clf = GridSearchCV(model,
parameters,
n_jobs=-1,
cv=5) # train을 5조각으로 나눠서 validation함
clf.fit(X_train, y_train)
>>> GridSearchCV(estimator=DecisionTreeClassifier(random_state=42),
param_grid={'max_depth': [3, 5, 7, 9, 11, 13, 15, 17],
'max_features': [0.3, 0.5, 0.7, 0.8, 0.9]})
clf.best_estimator_
>>> DecisionTreeClassifier(max_depth=9, max_features=0.5, random_state=42)
clf.best_score_
>>> 0.8566839930694389
pd.DataFrame(clf.cv_results_).sort_values("rank_test_score").head()

🛠️ RandomizedSearchCV()
param_distributions = {"max_depth":np.random.randint(3, 20, 10),
"max_features":np.random.uniform(0.5, 1, 10)}
clfr = RandomizedSearchCV(model,
param_distributions=param_distributions,
n_iter=10,
cv=5,
scoring="accuracy",
n_jobs=-1,
random_state=42, verbose=3)
clfr.fit(X_train, y_train)
clfr.best_estimator_
>>> DecisionTreeClassifier(max_depth=5, max_features=0.8176444614633067,
random_state=42)
clfr.best_params_
>>> {'max_features': 0.8176444614633067, 'max_depth': 5}
clfr.best_score_
>>> 0.8485405837664934
pd.DataFrame(clfr.cv_results_).nsmallest(5, "rank_test_score")

💡 parameters 설정 → 모델링 → .fit(X_train, y_train) → .best_estimator_ → .best_params_ → .best_score_ → pd.DataFrame(.cv_results_).nsmallest(5, "rank_test_score")
Best모델로 모델링 및 정확도 평가
# 베스트모델로 학습하기
best_model = clfr.best_estimator_
best_model.fit(X_train, y_train)
>>> DecisionTreeClassifier(max_depth=5, max_features=0.8176444614633067,
random_state=42)
# 예측하기
y_predict = best_model.predict(X_test)
#모델 평가
accuracy_score(y_test, y_predict)
>>> 0.9090909090909091
# 리포트 출력
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict))

sns.barplot(x = best_model.feature_importances_, y = best_model.feature_names_in_ )

⭐ Decision Tree 모델링 결론⭐
💡 머신러닝 모델링 순서
데이터 → EDA → Feature Engineering → 모델생성 → 하이퍼파라미터튜닝 → 정확도평가
- Feature Engineering에는 수치형 변수의 범주화, 결측치처리 등이 있다.
- 하이퍼파라미터튜닝에는 GridSearch와 RandomizedSearch가 있다.
- RandomizedSearch로 범위를 넓게 잡아 폭을 좁혀나간 후, 후보군을 골라 GridSearch를 시도하는 것도 한 방법이다.
- 모든 과정을 거친다고 성능이 꼭 좋아지는 것은 아니다.
'멋사 AISCOOL 7기 Python > INPUT' 카테고리의 다른 글
| [머신러닝] Titanic 데이터를 사용한 분류: Decision Tree, Binary Encoding, Entropy (0) | 2022.11.17 |
|---|---|
| [머신러닝] pima 데이터를 사용한 분류: Random Forest (0) | 2022.11.17 |
| [머신러닝] INTRO. 머신러닝프로젝트 주요단계(전처리, EDA, Feature Engineering, 교차검증, 하이퍼파라미터튜닝) (0) | 2022.11.17 |
| [머신러닝] INTRO. Definition, Tool, 알고리즘 유형 (0) | 2022.11.17 |
| 시각화 총정리: plotly (1) | 2022.10.28 |




