고정 헤더 영역
상세 컨텐츠
본문
1️⃣ Decision Tree Review
1-1. Decision Tree
- 분류와 회귀 작업 및 다중출력 작업도 가능한 다재다능한 머신러닝 방법론
- IF-THEN 룰에 기반해 해석이 용이함
- 일반적으로 예측 성능이 우수한 랜덤포레스트 방법론의 기본구조
- 💡 CART(Classification And Regression Tree) 훈련 알고리즘을 이용해 모델을 학습함
- 데이터 공간의 순도가 증가되게끔 영역을 구분하는 방법
- 즉 순수도는 최대가 되고, 불순도는 최소가 되게끔 계속해서 훈련을 해나가는 알고리즘
- 한 번에 한개의 변수를 사용하여 정확한 예측이 가능한 규칙들의 집합을 생성
- IF-THEN 규칙은 데이터 공간 상에서는 각 변수를 수직 분할한 것과 동일
- 아래의 data space에는 관측치가 존재하고, 이 관측치를 잘 분류하는 경계선을 찾아주는 것이 classification 관점에서 regression tree를 학습하는 과정이다.
- 가장 첫번째로 분류된 변수는 x → 첫번째 분할 경계선이 된다(세로선)
- 두번째로 분류된 변수는 y이다. → 두번째 분할 경계선이된다(가로선)

- IF-THEN 규칙을 이용해서 데이터 공간을 분할하여 분류나 예측을 하기 때문에 높은 해석력을 가짐
- 하지만 데이터의 작은 변화에 민감한 한계점을 가짐
- 하나의 관측치가 사라진다면 분류경계선의 변화가 크게 나타날 수 있다.
- 이를 Ensemble을 이용해 극복!
2️⃣ Ensemble Learning 소개
2-1. Ensemble learning
- Ensemble은 대중의 지혜(집단지성)의 개념과 유사하다!
- 무작위로 선택된 수천명의 사람에게 복잡한 질문을 하고 대답을 모은다고 가정한다면, 많은 경우 이렇게 모은 답이 한명의 전문가의 답보다 좋은 경우들이 많음
💡 Ensemble Learning
- 일련의 분류나 회귀모형들로부터 예측을 수집하면 가장 좋은 모델 하나 보다 더 좋은 예측 성능을 얻을 수 있다.
- 일반적으로 다양한 머신러닝 기법들을 앙상블 시켜주면 성능이 향상되는 효과를 얻을 수 있있다.
- ⭐ 랜덤포레스트 ⭐는 Decision Tree의 앙상블을 의미하고, 일반적을 굉장히 Robust하고 좋은 예측 성능을 보이는 것으로 알려져 있다.
2-2. Random Forest

- Decision Tree가 나무 1개라면, Random Forest는 숲으로 볼 수 있다.
- 랜덤포레스트는 새로운 관측치가 하나 들어오면 트리마다 결과물이 추출되고, 이 결과물들을 종합하여 최종결과물을 도출하게 된다.
- 그렇다면 이런 최종 결과물을 모으는 것에 대해 집중해서 보면 좋다.
2-3. 투표기반분류기
- 일반적으로 다수결에 의해 최종 결과물이 도출된다(majority vote)

3️⃣ Ensemble Learning 이론
3-1. Weak Learner & Strong Learner
- 다수결 투표 분류기는 앙상블에 포함된 개별 분류기 중 가장 뛰어난 것 보다 정확도가 높을 경우가 많다.
- 각 분류기가 약한 학습기(Weak Learner, 랜덤 추측보다 조금 더 높은 성능을 내는 분류기)일지라도 충분하게 많고 다양하다면 앙상블은 강한 학습기(Strong Learner)가 될 수 있다.

- week learner들의 성능을 majority voting을 이용해서 종합을 하면 strong learner가 된다.
- 즉 개별 learner들의 분류경계선은 선형이지만 strong learner의 분류경계선은 비선형이 되고 더 좋은 결과로 이어진다.
- 다양한 머신러닝 방법에 손쉽게 적용가능하다.
원리를 좀 더 이해해보자 ‼️
- 큰수의 법칙
- 동전던지기를 많이하면 할수록 앞면이 나올 확률이 높아진다.

- 이와 비슷하게 51%의 정확도를 가진 1000개의 분류기로 앙상블 모델을 구축한다고 가정할 때 가장 많은 클래스를 예측으로 삼는다면 75%의 정확도를 기대할 수 있으나, 단 모든 분류기가 완벽하게 독립적이고 오차에 상관관계가 없다는 가정이 있어야 한다
- 같은 데이터로 훈련시키다보면 이런 가정이 맞지 않은 경우가 많고, 분류기들이 같은 종류의 오차를 만들기 쉬워서 실제 앙상블 정확도는 이론 정확도에 비해 낮아진다.
3-2. Bagging과 Pasting
따라서 앙상블을 할 때 다양한 분류기를 만드는 것이 중요하다.
📍 방법1. 각기 다른 훈련 알고리즘을 사용
📍 방법2. Traing 데이터의 Subset을 무작위로 구성하여 분류기를 각기 다르게 학습시키는 방법
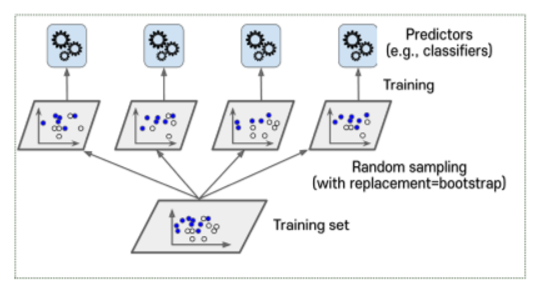
💡 Bagging(Bootstrap aggregating)
- Training 데이터에서 중복을 허용하여 샘플링 하는 방식
- 복원 추출
- 랜덤포레스트는 배깅이 적용된 트리로 Bagged Tree로 불리기도 한다.
💡 Pasting
- 중복을 허용하지 않고 샘플링하는 방식
- 비복원 추출
3-3. Out-of-Bag 평가
- Bagging을 이용하면 어떤 샘플은 한 예측기를 위해 여러번 샘플링되고 어떤 것은 전혀 선택되지 않을 수 있다.
- m개의 Training 데이터에서 m개의 데이터를 중복을 허용해서 샘플링할 때, 한번도 뽑히지 않는 관측치가 37% 가까이 될 수 있으며 이를 validation에 사용할 수 있다.
- 따라서 예측기가 훈련되는 동안에 학습에 반영되지 않는 샘플을 OOB샘플이라고 정의한다.
- 앙상블의 평가는 각 예측기의 OOB평가를 평균해서 얻을 수 있으며, 일종의 검증 데이터 역할을 한다고 볼 수 있다.
3-4. Random Forest
- 일반적으로 Bagging을 적용한 Decision Tree Ensemble 방법이다.
- 해석력은 Decision Tree에 비해 떨어질 수 있으나, 변수의 중요도를 각각의 Tree에서 순수도를 높인 결과를 종합한 기준으로 계산할 수 있다.
4️⃣ 실습
# 데이터
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression(solver="lbfgs", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
svm_clf = SVC(gamma="scale", random_state=42)
# Hard voting
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
# majority voting에 해당하는 classifier 결과물이 도출됨
voting_clf.fit(X_train, y_train)
# 정확도 계산
# 개별 classifier보다 성능이 더 개선됨을 알 수 있음
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
LogisticRegression 0.864
RandomForestClassifier 0.896
SVC 0.896 VotingClassifier 0.912
# soft voting
log_clf = LogisticRegression(solver="lbfgs", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
svm_clf = SVC(gamma="scale", probability=True, random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='soft')
voting_clf.fit(X_train, y_train)
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
LogisticRegression 0.864
RandomForestClassifier 0.896
SVC 0.896 VotingClassifier 0.92
# 랜덤포레스트
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
np.sum(y_pred == y_pred_rf) / len(y_pred) # almost identical predictions
>>> 0.976
# Out-oF-Bag evaluation
bag_clf = BaggingClassifier(
DecisionTreeClassifier(random_state=42), n_estimators=500,
bootstrap=True, oob_score=True, random_state=40)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_
>>> 0.8986666666666666
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)
>>> 0.912




